Inferencia distribuida#
Algunos modelos de lenguaje, incluyendo DeepSeek V3, DeepSeek R1, entre otros, son demasiado grandes para adaptarse a una GPU en una sola máquina. Xinference admite la ejecución de estos modelos en múltiples máquinas.
Added in version v1.3.0.
Motores compatibles#
Ahora, Xinference soporta los siguientes motores para ejecutar modelos en múltiples workers.
SGLang (soporta en v1.3.0)
vLLM (compatible desde v1.4.1)
MLX (soportado desde v1.7.1) actualmente no admite todos los modelos en modo distribuido. Por ahora, se soportan los siguientes tipos de modelos. Si tienes otras necesidades, no dudes en enviar un issue en xorbitsai/inference#issues para solicitar soporte.
DeepSeek v3 y R1
Qwen2.5-instruct y otros modelos con la misma arquitectura.
Qwen3 y otros modelos con la misma arquitectura de modelo.
Qwen3-moe y otros modelos con la misma arquitectura de modelo.
Usar#
Primero, necesita al menos 2 nodos trabajadores para admitir la inferencia distribuida. Consulte Ejecutar Xinference en un clúster para crear un clúster Xinference que incluya nodos supervisor y nodos trabajadores.
vLLM (v0.11.0+) Nota: A partir de la versión v0.11.0 de vLLM, el despliegue distribuido con vLLM requiere Xinference >= v1.17.1. Además del parámetro existente --n-worker, al iniciar el modelo también es necesario configurar tensor_parallel_size (establecido en el número de GPUs) y pipeline_parallel_size=1.
Luego, si está utilizando la interfaz web, seleccione el número deseado de máquinas como worker count en la configuración opcional; si está utilizando la línea de comandos, agregue --n-worker <número de máquinas> al iniciar el modelo. El modelo se iniciará en consecuencia en múltiples nodos de trabajo.
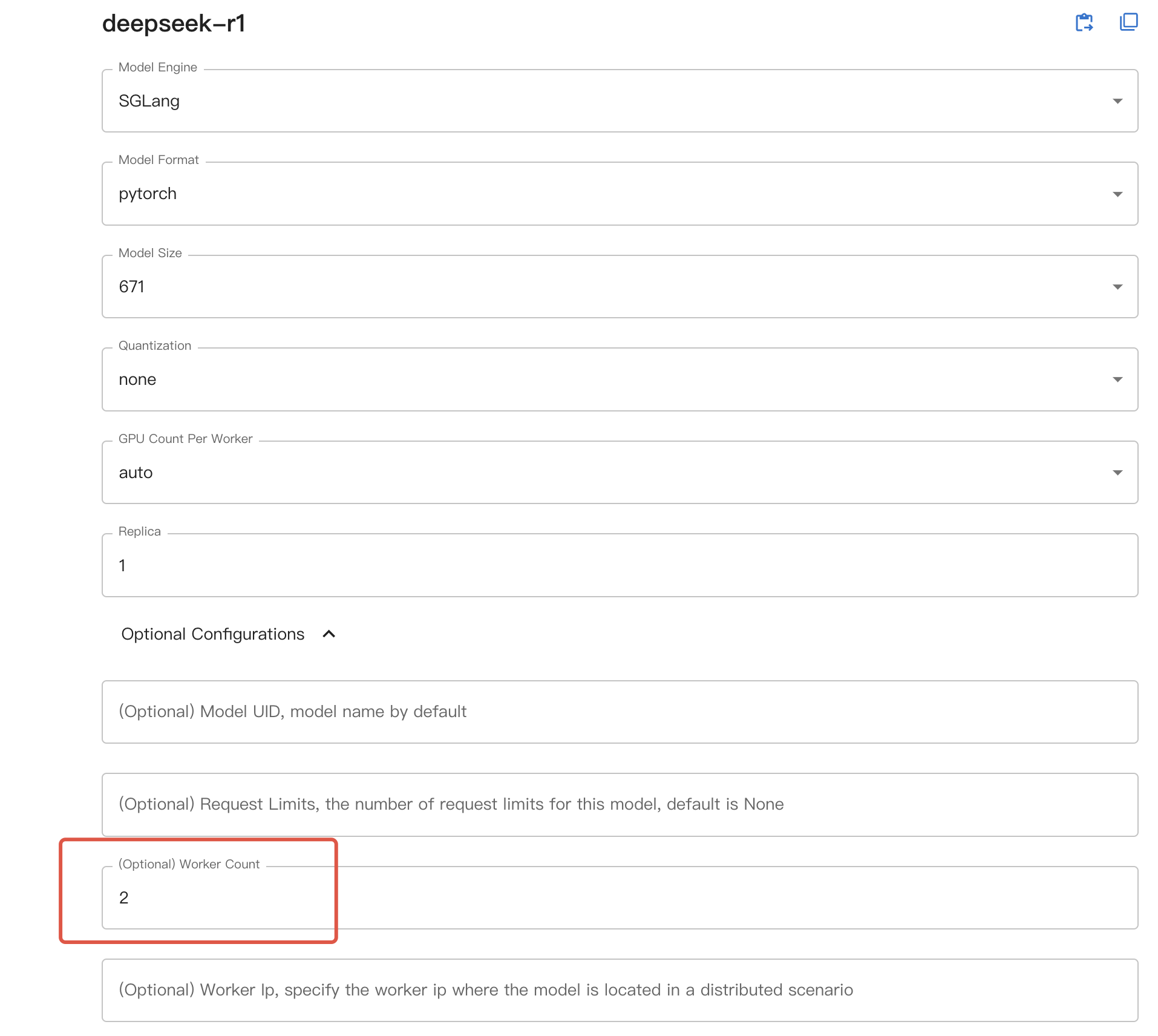
Al usar inferencia distribuida, GPU count en la interfaz web o --n-gpu en la línea de comandos ahora indica la cantidad de GPU por nodo de trabajo.