Motor de inferencia#
Xinference admite diferentes motores de inferencia para distintos modelos. Una vez que el usuario selecciona un modelo, Xinference elegirá automáticamente el motor adecuado.
llama.cpp#
Xinference actualmente admite xllamacpp desarrollado por el equipo de Xinference como backend de llama.cpp para su ejecución. llama.cpp se basa en la biblioteca de tensores ggml y soporta la inferencia de la serie de modelos LLaMA y sus variantes.
Advertencia
A partir de Xinference v1.5.0, xllamacpp se convierte en la opción predeterminada para llama.cpp, y llama-cpp-python queda en desuso; desde Xinference v1.6.0, llama-cpp-python ha sido eliminado.
Consulte la definición de la estructura common_params en common.h de llama.cpp para configurar los parámetros.
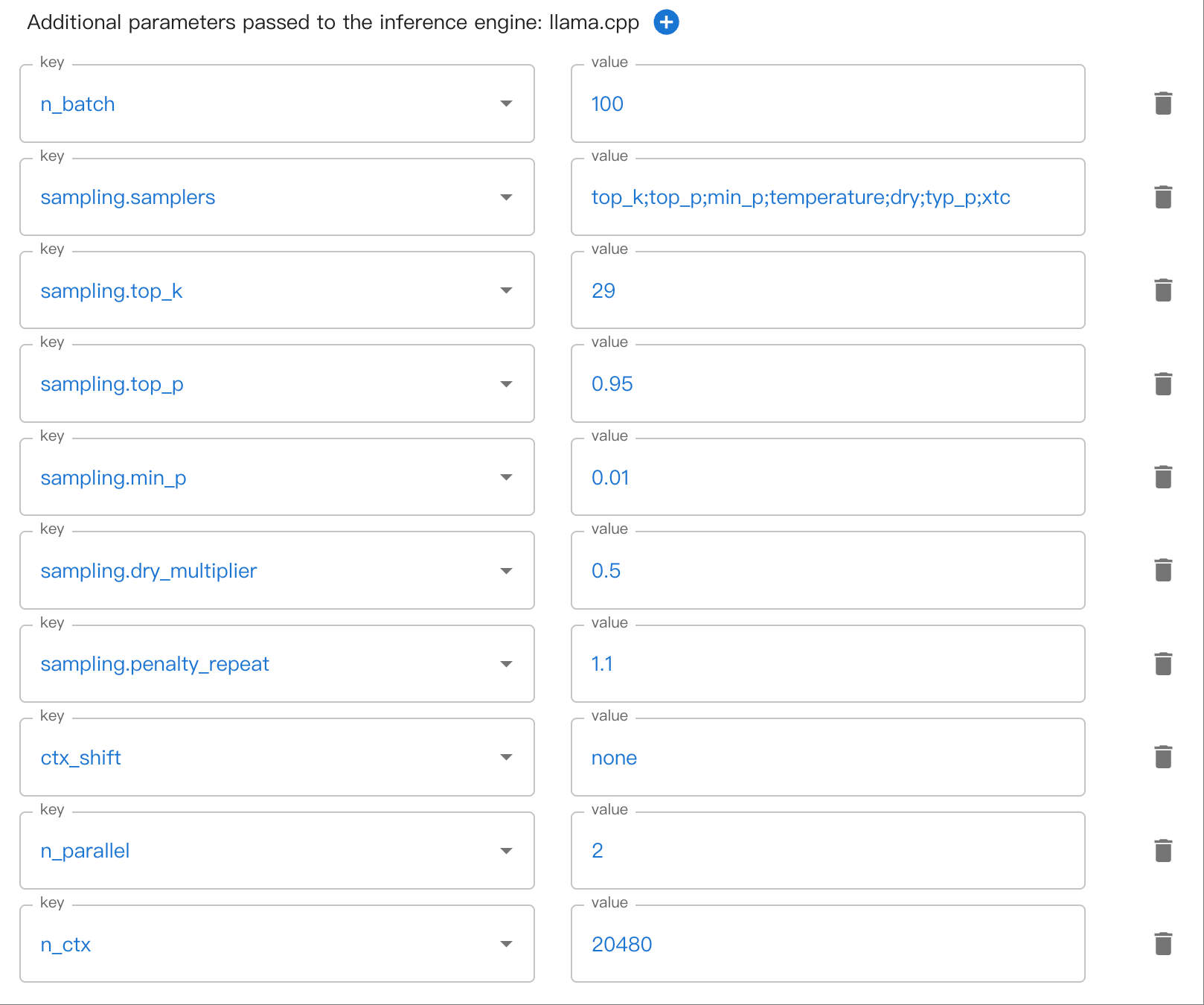
Puede haber parámetros anidados en varios niveles. Por ejemplo, sampling.top_k. Utilice . para separar los parámetros anidados.
Aquí hay un ejemplo de cómo configurar los parámetros de muestreo anidado en la WebUI:
NGL automático#
Added in version v1.6.1: A partir de v1.6.1, cuando no se especifica n-gpu-layers (por defecto -1), se habilitará automáticamente la función de estimación de capas de GPU.
Esta función puede configurar automáticamente el número de capas de GPU (NGL) para el backend de llama.cpp. Tenga en cuenta que esto no es un cálculo preciso, por lo que el resultado de -ngl puede no ser óptimo y aún es posible encontrar errores de memoria insuficiente.
Actualmente NGL automático no tiene soporte oficial. Consulte el siguiente issue para más detalles:
Nuestra implementación se basa en el NGL automático de Ollama, pero tiene algunas diferencias:
Usamos la información del dispositivo proporcionada por xllamacpp.
Hemos eliminado la compatibilidad con algunas arquitecturas poco comunes, que utilizarán la lógica de cálculo predeterminada.
Si el NGL automático falla, intentaremos cargar todo en la GPU.
No soportamos la incrustación del proyector multimodal en el GGUF del modelo. Este formato de modelo se encuentra actualmente en etapa experimental.
Preguntas frecuentes#
Server error: {“code”: 500, “message”: “failed to process image”, “type”: “server_error”}
Registro del servidor:
encoding image or slice... slot update_slots: id 0 | task 0 | kv cache rm [10, end) srv process_chun: processing image... ggml_metal_graph_compute: command buffer 0 failed with status 5 error: Internal Error (0000000e:Internal Error) clip_image_batch_encode: ggml_backend_sched_graph_compute failed with error -1 failed to encode image srv process_chun: image processed in 2288 ms mtmd_helper_eval failed with status 1 slot update_slots: id 0 | task 0 | failed to process image, res = 1
Puede deberse a memoria insuficiente. Puedes intentar reducir
n_ctxpara solucionarlo.Server error: {“code”: 400, “message”: “the request exceeds the available context size. try increasing the context size or enable context shift”, “type”: “invalid_request_error”}
Si estás utilizando la funcionalidad multimodal,
ctx_shiftestará desactivado por defecto. Intenta aumentarn_ctxo reducirn_parallelpara incrementar el tamaño del contexto de cada slot.Server error: {“code”: 500, “message”: “Input prompt is too big compared to KV size. Please try increasing KV size.”, “type”: “server_error”}
Registro del servidor:
ggml_metal_graph_compute: command buffer 1 failed with status 5 error: Insufficient Memory (00000008:kIOGPUCommandBufferCallbackErrorOutOfMemory) graph_compute: ggml_backend_sched_graph_compute_async failed with error -1 llama_decode: failed to decode, ret = -3 srv update_slots: failed to decode the batch: KV cache is full - try increasing it via the context size, i = 0, n_batch = 2048, ret = -3
Puede deberse a un fallo en la creación de la cache KV. Puedes solucionarlo reduciendo
n_ctx, aumentandon_parallelo ajustando el parámetron_gpu_layerspara cargar parte del modelo en la GPU. Ten en cuenta que si solo procesas solicitudes de inferencia en serie, aumentarn_parallelno mejorará el rendimiento.
transformers#
Transformers es compatible con la gran mayoría de los modelos más recientes. Es el motor predeterminado para modelos en formato Pytorch.
vLLM#
vLLM es un motor de inferencia de modelos de lenguaje grandes muy eficiente y fácil de usar.
vLLM tiene las siguientes características:
Rendimiento de inferencia líder
Usa PagedAttention para gestionar eficientemente la memoria de claves y valores de atención.
Procesamiento por lotes continuo de solicitudes entrantes
Núcleo optimizado de CUDA
Xinference seleccionará automáticamente vLLM como motor de inferencia cuando se cumplan las siguientes condiciones:
El formato del modelo es
pytorch,gptq,awq,fp4,fp8obnb.Cuando el formato del modelo es
pytorch, la opción de cuantización debe sernone.Cuando el formato del modelo es
awq, la opción de cuantificación debe serInt4.Cuando el formato del modelo sea
gptq, las opciones de cuantización deben serInt3,Int4oInt8.El sistema operativo es Linux y tiene al menos un dispositivo compatible con CUDA.
El campo
model_familyde los modelos personalizados y el campomodel_namede los modelos integrados están en la lista de soporte de vLLM.
Actualmente, los modelos compatibles son:
code-llama,code-llama-instruct,code-llama-python,deepseek,deepseek-chat,deepseek-coder,deepseek-coder-instruct,deepseek-r1-distill-llama,gorilla-openfunctions-v2,HuatuoGPT-o1-LLaMA-3.1,llama-2,llama-2-chat,llama-3,llama-3-instruct,llama-3.1,llama-3.1-instruct,llama-3.3-instruct,minicpm5-1b,tiny-llama,wizardcoder-python-v1.0,wizardmath-v1.0,Yi,Yi-1.5,Yi-1.5-chat,Yi-1.5-chat-16k,Yi-200k,Yi-chatcodestral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3,mistral-large-instruct,mistral-nemo-instruct,mistral-v0.1,openhermes-2.5,seallm_v2Baichuan-M2,codeqwen1.5,codeqwen1.5-chat,deepseek-r1-distill-qwen,DianJin-R1,fin-r1,HuatuoGPT-o1-Qwen2.5,KAT-V1,marco-o1,qwen1.5-chat,qwen2-instruct,qwen2.5,qwen2.5-coder,qwen2.5-coder-instruct,qwen2.5-instruct,qwen2.5-instruct-1m,qwenLong-l1,QwQ-32B,QwQ-32B-Preview,seallms-v3,skywork-or1,skywork-or1-preview,XiYanSQL-QwenCoder-2504llama-3.2-vision,llama-3.2-vision-instructbaichuan-2,baichuan-2-chatInternLM2ForCausalLMqwen-chatmixtral-8x22B-instruct-v0.1,mixtral-instruct-v0.1,mixtral-v0.1cogagentglm-edge-chat,glm4-chat,glm4-chat-1mcodegeex4,glm-4vseallm_v2.5orion-chatqwen1.5-moe-chat,qwen2-moe-instructCohereForCausalLMdeepseek-v2-chat,deepseek-v2-chat-0628,deepseek-v2.5,deepseek-vl2deepseek-prover-v2,deepseek-r1,deepseek-r1-0528,deepseek-v3,deepseek-v3-0324,Deepseek-V3.1,moonlight-16b-a3b-instructdeepseek-r1-0528-qwen3,qwen3minicpm3-4binternlm3-instructgemma-3-1b-itglm4-0414minicpm-2b-dpo-bf16,minicpm-2b-dpo-fp16,minicpm-2b-dpo-fp32,minicpm-2b-sft-bf16,minicpm-2b-sft-fp32,minicpm4Ernie4.5Qwen3-Coder,Qwen3-Instruct,Qwen3-Thinkingglm-4.5,GLM-4.6,GLM-4.7gpt-ossseed-ossQwen3-Next-Instruct,Qwen3-Next-ThinkingDeepSeek-V3.2,DeepSeek-V3.2-ExpMiniMax-M2,MiniMax-M2.5,MiniMax-M2.7GLM-4.7-Flashglm-5,glm-5.1DeepSeek-V4-Flash,DeepSeek-V4-Pro
SGLang#
SGLang cuenta con un runtime de inferencia de alto rendimiento basado en RadixAttention. Acelera significativamente la ejecución de programas complejos de LLM al reutilizar automáticamente la caché KV entre múltiples llamadas. También admite otras técnicas comunes de inferencia, como el procesamiento por lotes continuo y el procesamiento paralelo de tensores.
MLX#
MLX proporciona una forma de ejecutar LLM de manera eficiente en chips Apple Silicon. Cuando el modelo incluye el formato MLX, se recomienda que los usuarios de Mac con chip Apple Silicon utilicen el motor MLX.