Multimodal#
Aprende a usar LLM para procesar imágenes y audio.
visión#
Con la capacidad vision, puede hacer que el modelo reciba imágenes y responda preguntas sobre ellas. En Xinference, esto significa que ciertos modelos pueden procesar entradas de imágenes durante las conversaciones a través de la API de Chat.
Lista de modelos compatibles#
En Xinference, los modelos que admiten la función vision son los siguientes:
qwen-vl-chat
deepseek-vl-chat
omnilmm
cogvlm2
MiniCPM-Llama3-V 2.5
glm-edge-v
Inicio rápido#
El modelo puede obtener imágenes de dos maneras principales: mediante el enlace de la imagen o pasando la imagen codificada en base64 directamente en la solicitud.
Ejemplo de uso del cliente OpenAI#
import openai
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "http://i.epochtimes.com/assets/uploads/2020/07/shutterstock_675595789-600x400.jpg",
},
},
],
}
],
)
print(response.choices[0])
Subir una imagen codificada en Base64#
import openai
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
b64_img = encode_image(image_path)
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{b64_img}",
},
},
],
}
],
)
print(response.choices[0])
Limita la cantidad de imágenes por ronda de diálogo.#
Para los modelos visuales que utilizan el backend VLLM, puedes limitar la cantidad de imágenes que se pueden procesar por cada ronda de conversación mediante el parámetro limit_mm_per_prompt. Esto ayuda a controlar el uso de memoria y mejorar el rendimiento.
# Launch model with image count limitation using Python client
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
# Launch model and set maximum 4 images per conversation turn
model_uid = client.launch_model(
model_name="qwen2.5-vl-instruct",
model_engine="vLLM",
model_format="pytorch",
quantization="none",
model_size_in_billions=3,
limit_mm_per_prompt="{\"image\": 4}"
)
O bien, puedes iniciar el modelo desde la línea de comandos:
# Launch model with image count limitation using CLI
xinference launch \
--model-engine vLLM \
--model-name qwen2.5-vl-instruct \
--size-in-billions 3 \
--model-format pytorch \
--quantization none \
--limit_mm_per_prompt "{\"image\":4}"
Para la interfaz web, puedes configurar el parámetro limit_mm_per_prompt en el formulario del motor vLLM:
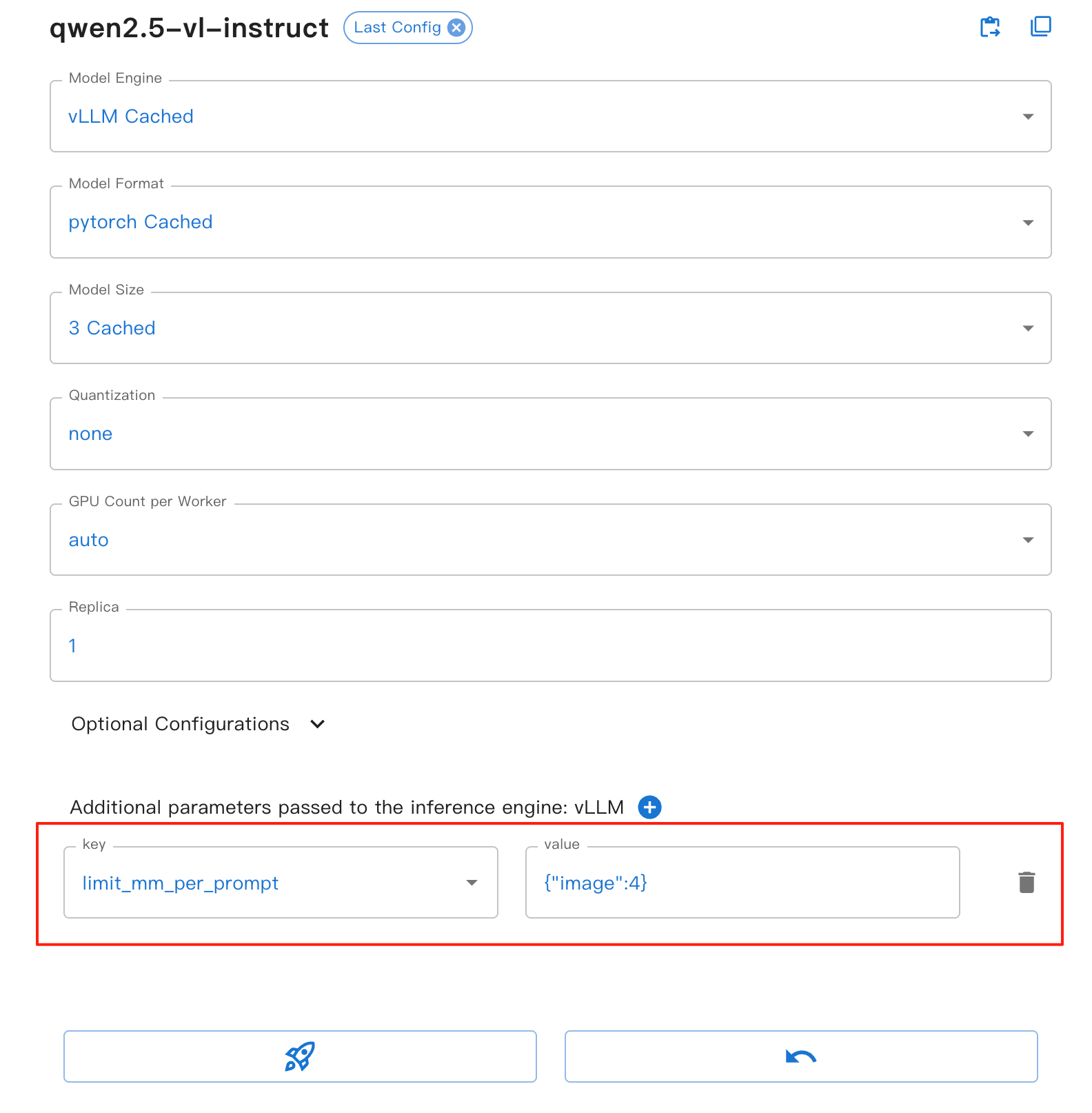
Este parámetro ofrece los siguientes beneficios:
image: Establece el número máximo de imágenes permitidas por turno de conversación.
Ayuda a prevenir el desbordamiento de memoria, especialmente al procesar múltiples imágenes.
Mejorar la estabilidad y el rendimiento de la inferencia del modelo.
Aplicable a todos los modelos visuales basados en VLLM.
Nota
El parámetro limit_mm_per_prompt solo tiene efecto al utilizar el backend VLLM. Si tu modelo utiliza otro backend, este parámetro se ignorará.
Puedes encontrar más ejemplos sobre las capacidades de vision en el cuaderno de tutorial.
Aprenda a usar las capacidades visuales de LLM mediante el ejemplo de uso de qwen-vl-chat.
audio#
A través de la función de «audio», su modelo puede recibir audio y realizar análisis de audio o generar respuestas de texto directamente basadas en instrucciones de voz. En Xinference, esto significa que ciertos modelos pueden procesar entradas de audio durante las conversaciones a través de la API de Chat.
Lista de modelos compatibles#
La función de «audio» en Xinference admite los siguientes modelos:
Inicio rápido#
El audio puede proporcionarse al modelo de dos maneras principales: mediante un enlace de imagen o pasando directamente una URL de audio en la solicitud.
Chat con audio#
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model(<MODEL_UID>)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3",
},
{"type": "text", "text": "What's that sound?"},
],
},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{
"role": "user",
"content": [
{"type": "text", "text": "What can you do when you hear that?"},
],
},
{
"role": "assistant",
"content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property.",
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac",
},
{"type": "text", "text": "What does the person say?"},
],
},
]
print(model.chat(messages))