Modelos de aprendizaje automático tradicional (experimentales)#
Aprende a usar Xinference para inferir modelos tradicionales de aprendizaje automático. En Xinference, estos modelos flexibles y escalables se denominan modelos flexibles.
Added in version v1.7.1: Esta función es pública desde la versión v1.7.1, aunque la API actualmente es inestable y podría cambiar en iteraciones posteriores.
Introducción#
Los modelos tradicionales de aprendizaje automático aún pueden desempeñar un papel importante en el ecosistema centrado en modelos grandes.
Xinference ofrece una capacidad de extensión flexible para inferir modelos de machine learning tradicionales. Tiene soporte integrado para cargar y ejecutar los siguientes tipos de modelos:
El HuggingFace Pipeline que utiliza modelos alojados en HuggingFace se puede emplear para tareas como clasificación.
Usa el ModelScope Pipeline del modelo en ModelScope, se puede usar para tareas como clasificación.
YOLO se utiliza para la detección de imágenes y tareas relacionadas con la visión por computadora.
Xinference soporta varios modelos tradicionales de aprendizaje automático. Para cada una de las categorías mencionadas, demostraremos paso a paso cómo realizar inferencias en la plataforma Xinference mediante un ejemplo representativo.
Casos de soporte de modelos integrados#
HuggingFace Pipeline modelo#
Primero, tomamos como ejemplo FacebookAI/roberta-large-mnli. Este modelo pertenece a la categoría de clasificación de cero disparos. Para otros tipos de modelos, al registrarlos solo es necesario especificar la tarea correspondiente (que también es el parámetro de Pipeline).
Descarga el modelo en la siguiente ruta:
/path/to/roberta-large-mnli
A continuación, demostramos cómo registrar el modelo flexible en la interfaz web de Xinference. En ejemplos posteriores, a menos que sea necesario, omitiremos las operaciones de la interfaz y nos centraremos en la lógica central.
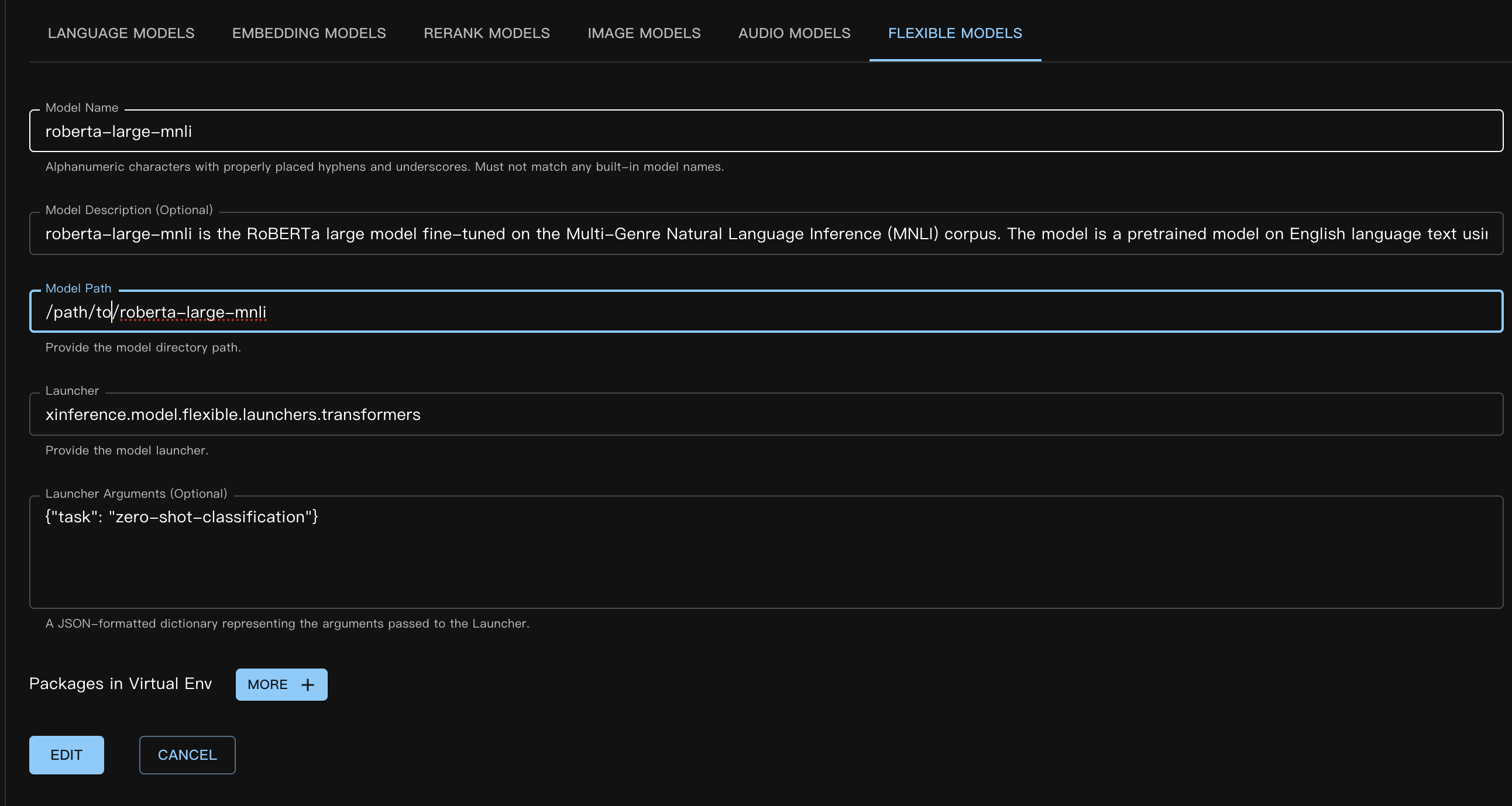
El archivo JSON del modelo personalizado correspondiente es el siguiente:
{
"model_name": "roberta-large-mnli",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "roberta-large-mnli is the RoBERTa large model fine-tuned on the Multi-Genre Natural Language Inference (MNLI) corpus. The model is a pretrained model on English language text using a masked language modeling (MLM) objective.",
"model_uri": "/path/to/roberta-large-mnli",
"launcher": "xinference.model.flexible.launchers.transformers",
"launcher_args": "{\"task\": \"zero-shot-classification\"}",
"virtualenv": {
"packages": [],
"inherit_pip_config": true,
"index_url": null,
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Consulte la sección register_custom_model para aprender cómo registrar modelos mediante código o línea de comandos.
A continuación, en la interfaz web, seleccione Modelo de inicio / Modelo personalizado / Modelo flexible para cargar el modelo. El proceso de carga es el mismo que para otros tipos de modelos.
Al usar la línea de comandos, recuerde especificar el parámetro --model-type flexible.
Una vez que el modelo se haya cargado correctamente, podemos realizar la inferencia de las siguientes maneras.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/flexible/infers' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "roberta-large-mnli",
"args": [
"one day I will see the world",
["travel", "cooking", "dancing"]
]
}'
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("roberta-large-mnli")
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
model.infer(sequence_to_classify, candidate_labels)
{"sequence":"one day I will see the world","labels":["travel","cooking","dancing"],"scores":[0.9799638986587524,0.010605016723275185,0.009431036189198494]}
ModelScope Pipeline modelo#
ModelScope Pipeline es muy similar al modelo Huggingface, la única diferencia radica en el launcher utilizado.
Tomemos como ejemplo un modelo de clasificación zero-shot en ModelScope. El modelo es iic/nlp_structbert_zero-shot-classification_chinese-base.
Aquí utilizamos la función de entorno virtual de modelos de Xinference. Debido a que el modelo utilizado en este ejemplo requiere transformers==4.50.3 para funcionar correctamente. Para aislar el entorno de ejecución, al registrar el modelo empleamos el entorno virtual.
La sintaxis para especificar paquetes personalizados al registrar un modelo es la misma que para los paquetes comunes, pero con algunas situaciones especiales. Dado que el entorno virtual aún se basa en los site-packages del intérprete de Python donde se ejecuta Xinference, necesitamos incluir explícitamente #system_numpy#. Los nombres de los paquetes se envuelven con #system_xx# para asegurar que el entorno virtual sea consistente con el entorno base al crearse; de lo contrario, es fácil que se produzcan errores en tiempo de ejecución.
Método de registro (Web UI):
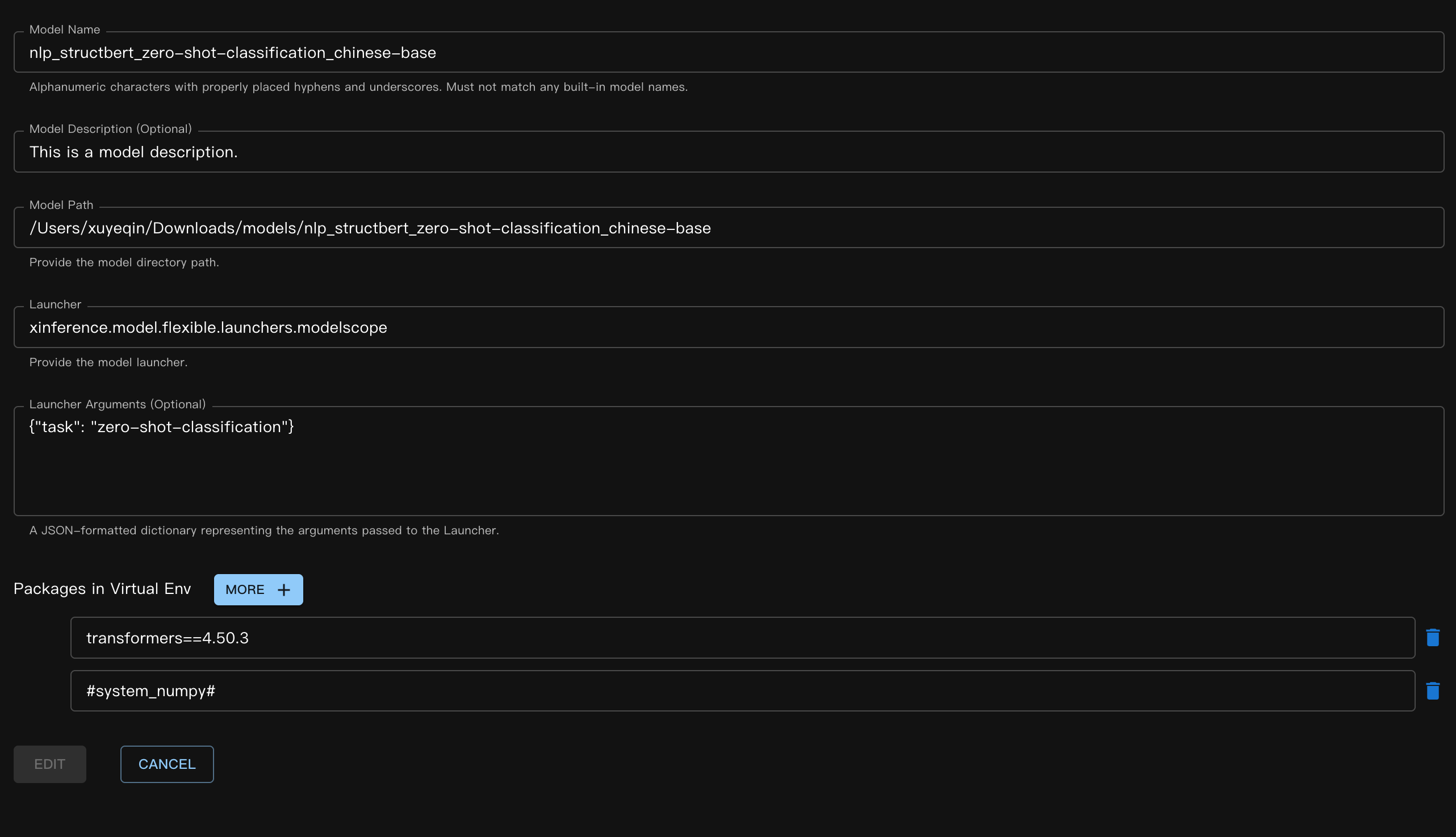
Archivo JSON correspondiente:
{
"model_name": "nlp_structbert_zero-shot-classification_chinese-base",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "This is a model description.",
"model_uri": "/Users/xuyeqin/Downloads/models/nlp_structbert_zero-shot-classification_chinese-base",
"launcher": "xinference.model.flexible.launchers.modelscope",
"launcher_args": "{\"task\": \"zero-shot-classification\"}",
"virtualenv": {
"packages": [
"transformers==4.50.3",
"#system_numpy#"
],
"inherit_pip_config": true,
"index_url": "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple",
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Traducción del modelo:
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/flexible/infers' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "nlp_structbert_zero-shot-classification_chinese-base",
"args": [
"世界那么大,我想去看看"
],
"candidate_labels": ["家居", "旅游", "科技", "军事", "游戏", "故事"]
}'
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("nlp_structbert_zero-shot-classification_chinese-base")
labels = ['家居', '旅游', '科技', '军事', '游戏', '故事']
sentence = '世界那么大,我想去看看'
model.infer(sentence, candidate_labels=labels)
{"labels":["旅游","故事","游戏","家居","科技","军事"],"scores":[0.5115892291069031,0.1660086065530777,0.11971458047628403,0.08431519567966461,0.06298774480819702,0.05538458004593849]}%
YOLO#
YOLO es un modelo popular de detección de objetos en tiempo real, ampliamente utilizado en escenarios de detección de imágenes y análisis de video.
Primero, descarga los pesos de YOLO. Aquí tomamos como ejemplo el archivo yolov11s.pt.
Archivo JSON de definición del modelo:
{
"model_name": "yolo11s",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "YOLO is a popular real-time object detection model, widely used in image detection and video analysis scenarios.",
"model_uri": "/Users/xuyeqin/Downloads/models/yolo11s.pt",
"launcher": "xinference.model.flexible.launchers.yolo",
"launcher_args": "{}",
"virtualenv": {
"packages": [
"ultralytics",
"#system_numpy#"
],
"inherit_pip_config": true,
"index_url": "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple",
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Traducción del modelo:
import requests
from PIL import Image
import io
import base64
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("yolo11s")
url = "https://ultralytics.com/images/bus.jpg"
response = requests.get(url)
response.raise_for_status()
img = Image.open(io.BytesIO(response.content))
buffered = io.BytesIO()
img.save(buffered, format="JPEG")
img_bytes = buffered.getvalue()
img_base64 = base64.b64encode(img_bytes).decode('utf-8')
model.infer(source=img_base64)
[[{'name': 'bus',
'class': 5,
'confidence': 0.93653,
'box': {'x1': 13.9521, 'y1': 227.0665, 'x2': 800.17688, 'y2': 739.13965}},
{'name': 'person',
'class': 0,
'confidence': 0.89741,
'box': {'x1': 669.89709,
'y1': 389.82065,
'x2': 809.58966,
'y2': 879.65491}},
{'name': 'person',
'class': 0,
'confidence': 0.88205,
'box': {'x1': 52.37262, 'y1': 397.83792, 'x2': 248.506, 'y2': 905.98212}},
{'name': 'person',
'class': 0,
'confidence': 0.8706,
'box': {'x1': 222.58685,
'y1': 405.93442,
'x2': 345.02032,
'y2': 859.52789}},
{'name': 'person',
'class': 0,
'confidence': 0.66505,
'box': {'x1': 0.28522, 'y1': 548.60931, 'x2': 81.25904, 'y2': 871.59076}}]]
Escribir un modelo flexible personalizado#
Primero, implementamos un launcher personalizado simple para la puntuación de sentimientos. En este ejemplo, no utilizamos ningún peso de modelo real, por lo que la función load no realiza ninguna operación de carga de modelo.
# my_flexible_model.py
from xinference.model.flexible import FlexibleModel
class RuleBasedSentimentModel(FlexibleModel):
def load(self):
self.pos_words = self.config.get("pos", ["good", "happy", "great"])
self.neg_words = self.config.get("neg", ["bad", "sad", "terrible"])
def infer(self, text: str):
score = 0
words = text.lower().split()
for w in words:
if w in self.pos_words:
score += 1
elif w in self.neg_words:
score -= 1
return {"score": score}
def launcher(model_uid: str, model_spec: FlexibleModel, **kwargs) -> FlexibleModel:
# get model path,
# in this example, we do not use it, so it's empty
model_path = model_spec.model_uri
return RuleBasedSentimentModel(model_uid=model_uid, model_path=model_path, config=kwargs)
La definición del modelo JSON es la siguiente:
{
"model_name": "my-flexible-model",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "This is a model description.",
"model_uri": "/path/to/model",
"launcher": "my_flexible_model.launcher",
"launcher_args": "{\"pos\": [\"good\", \"happy\", \"great\", \"nice\"]}",
"virtualenv": {
"packages": [],
"inherit_pip_config": true,
"index_url": null,
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Aquí extendemos el modelo pasando un valor personalizado de pos.
Finalmente, verificamos el resultado:
from xinference.client import Client
client = Client("http://127.0.0.1:9997")
model = client.get_model("my-flexible-model")
model.infer("I feel nice and am happy today")
{'score': 2}
Conclusión#
El launcher de modelos flexibles integrado en Xinference se encuentra en Github. ¡Las contribuciones para añadir soporte a más modelos de aprendizaje automático clásico son bienvenidas!